基於縱橫碼的語音輸入法初探
常州技術師範學院計算機科學系
鄭成增、徐鴻翔、陳志鋒、尹長青
一、前言
1、縱橫碼簡介
縱橫漢字編碼法是一種具有直觀性和科學性的漢字編碼法,也是一種按照字形和字義對漢字進行分類的一種分類法,它用“0”-“9”十個數字作為基本碼元,對漢字的筆形、部首和整個漢字及基本詞組進行編碼。它類似四角號碼字典的漢字取碼法,是一種純數碼編碼方案。
2、語音識別技術現狀
語音識別技術並非是一項新的技術,事實上,Bellano ratories早在本世紀五十年代就開始進行語音識別的試驗,並取得了一定成果。然而,它的應用卻被當時的技術水平所限制,那時的語音識別系統只能夠識別那些隔裂開來的字詞。如果你想讓電腦能聽明白你所說的語音,你就必須用靜音(停機)將所說的話分展開來。此外,大多數系統還要求講話者花費數小時去對它進行訓練,以使客觀存在能聽懂他的(或她的)個人發音,這是極不方便的,這對於推廣應用,受到很大限制。這種制約在當前為個人電腦所提供的語音識別產品中依然存在。譬如要求使用者對它進行訓練的系統有kurzweil,Dragon
System以及IMD的產品,通常可支持四人使用,在詞匯量方面要求或者限制在一定數量範圍內,有的甚至只限於某種引起專用詞匯。
3、縱橫語音輸入可行性分析
目前,特定的少量詞匯孤立單詞語言識別系統的識別率已達99%以上,且所需聲卡已作為PC的標準選用件。縱橫碼採用0-9十個數字錄入漢字,是一種純數字碼輸入方案,與漢字讀音語音語義及安形相對無關。利用幾個數字的語音編碼輸入漢字,採用這種方案僅對十個數字進行識別,音域範圍大大減小,完全可超過99%的識別率,這種識別率只取決於該編碼系統的重碼等因素。而該編碼系統是一種重碼率極低的系統。因而用縱橫碼進行實用的語音錄入是可行的,加上縱橫的易學性、快速性,使人們利用縱橫碼輸入法,採用最自然的輸入方式--語音輸入漢字成為可能。
二、語音識別原理分析
1、識別過程
目前,大多數語音識別系統多採用了模式匹配的原理。根據這個原理,未知語音的本模式要與已知語言的參考模式(標準模式)逐一進行比較,達到與參考模式相匹配,便可作為識別結果輸出。下圖所示是根據模式匹配原理過程的自動語言識別系統的原理性方塊圖。(圖一)

圖一 自動語音識別系統原理性方塊圖
該圖中,未知(待識別)語音經過話筒變換成電信號(即圖中的語音信號)後加在識別系統輸入端,首先要經過預處理。預處理包括反混疊失真濾波器,預加重器、端口檢驗器和模數轉換器。
經過預處理後,語音信號的特徵被提取出來。被提取的特徵包括:短時平均能量或幅度、短時平均零率、短時自相關函數、線性預測系數(或反射系數或對面積比參數)、清音/濁音標誌、基音頻率、短時傅裡葉變換、倒譜、共振峰等語音的特徵參數的時間序列便構成了語音的本模式,將其與已經存儲在機內的參考模式逐一進行比較(模式匹配),歸納出獲得最佳匹配模式(由判決規則決定)便中識別結果。參考模式是在系統使用前獲得並存儲起來的。為此,要輸入一系列已知語音信號,提取它們的特徵作為參考模式,這一過程稱為訓練過程。在訓練階段,開關S置於“訓練”,接點。
2、語音編碼研究初步
我們在噪音測試儀上很清楚地測得0-9十個數字時間波形圖(圖二):
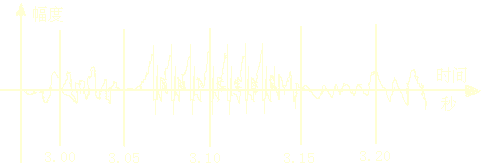
在PC機上(插Creative SB16卡)也可用話筒拾取語音信號。經聲卡放大以及低通濾波後,可按8KHZ頻率取樣,信號按256點為一幀,幀移為128點,採用差分脈沖編碼調制(PPCM)。這樣可對0-9十個數字進行編碼,從而組合為縱橫漢字的語音編碼序列。
3、語音特徵提取方法
線性預測又叫線性預測分析,更常被稱為線性預測編碼,簡寫為LPC,準確地說,線性預測是指最佳線性向前一步純預測。從計算量的觀點來看,線性預測編碼(LPC)是種最吸引人的語音特徵提取技術。LPC分析的全極點性質能夠精確地估計語音的譜峰。不過,只有對符合全極點模型的語音來說才是這樣的。對於鼻音和不少輔音來說,LPC對譜峰帶寬的估計一般都超限了。因而,採用此法還需要進行一定的平滑解調處理。語音的線性預測,其基本思想是:主要信號的每個取樣值,可以用它過去的若干個取樣值的加權和(線性組合)來表示;各加權系數的確定原則是使預測誤差的均方值最小(即遵循所謂最小均方準則)。預測誤差的定義為真實取樣值與預測值之差。如果利用過去P個取樣值來進行預測,稱為P階線性預測。線性預測是表示語音信號波形的重要方法之一,有很廣泛的應用。用其能夠以少數低資訊率的時變參數來表示語音信號波形還能夠對語音參數(如基音頻率、共振峰、功率譜等)進行精確有估計,具體方法常採用Levinsion-Durbim(有時也用非線性時間歸一化進行處理,在此不做介紹)。
三、Levinson-Durbin算法
求取信號的模型參數可以通過線性預測來完成,而線性預測誤差功率可以由式
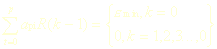
所表示的Yule-Walker方程解出。通過解上式,可以求取線性預測系數及預測誤差功率。
將上式寫成矩陣形式,並注意平穩隨機信號的相關函數的對稱性,可以得到下面的結果:
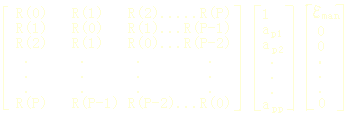
值得注意的是,上列方程組的系數矩陣中,沿任何一條對角線上的元素都相同,這樣的矩陣稱為Toeplitz性質;同時系數矩陣還是一個對長矩陣。利用系數矩陣的對長Toeplitz性質,提出了一種高效算法來求解該方程組,這就是著名的Levinson-Durbin算法,簡稱為Levinson算法,該算法的運算量數量級為O(P2),而線性方程組的一般解法的運算量數量級為O(P3),後者比前者要大得多。Levinson算法是一個迭代運算過程。它從最低階預測器開始由低階到高階,逐階進行遞推運算,亦即,總是由前一階預測器系數遞推計算出下一階預測器系數。這樣,迭代的最後結果,不僅求出了所要求的P階預測器的系數,而且得到了所有低階預測器的系數。下圖(圖三)描述了迭代運算過程。

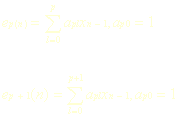
圖三 由P階預測器遞推計算P+1階預測器
在該圖中,最上面表示了由過去P個取樣值預測當前值?n;下面依次畫出了1階、2階、3階...P階預測器的預測系數;旁邊寫出了各階預測器的預測誤差。預測系數有兩個下標,第一個下標表示階數,第二個下標指示該階預測器系數的序數。用該方法提取的0-9的線性預測系數進行了初步的運算,其結果有待進一步分析處理。
四、結束語
縱橫編碼較其它編碼方案,實現語言輸入有其更大的優越,因它是一種純數字作基本碼元,實現來有其更大的可行性和方便性。但實現語言輸入是一種技術性十分繁雜的研究,本文僅就有關問題提出一些原理性思路和初步解決方法,在連續數字讀音的切分、連續語音識別、非特定人聲音的識別等方面尚有大量工作要做。
參考文獻:
[1]錢培德等CCDOS操作系統大全(續集)-清華大學出版社(1993)
返回上頁 |